
A realização de agentes de lucidez sintético diretamente no hardware do usuário traz vantagens de privacidade e dispêndio. Se você procura entender porquê rodar o OpenClaw em suas placas RTX ou em sistemas com NVIDIA DGX, o processo envolve o uso de ferramentas porquê WSL e backends otimizados.
O OpenClaw, anteriormente sabido porquê Clawdbot, opera porquê um assistente sítio capaz de memorizar conversas e utilizar o contexto de arquivos pessoais para automatizar tarefas na máquina.
É por isso que agente foi adquirido pela OpenAI e é considerado porquê um marco dentro da breve história da IA generativa, pois se destaca pela capacidade de adaptação e expansão através de novas habilidades.
Outrossim, agora, ao contrário de soluções em nuvem, que podem gerar custos recorrentes e exigem o envio de dados para servidores externos, a realização sítio utiliza os Tensor Cores das placas GeForce RTX para correr operações de IA.

Veja porquê fazer para configurar essa instrumento no Windows:
Riscos e precauções de segurança
Antes de iniciar a instalação, é necessário compreender as implicações de manter um agente de IA com entrada aos seus dados. Os dois principais vetores de risco envolvem o vazamento de informações pessoais e a exposição a códigos maliciosos através de ferramentas conectadas ao bot.
Para mitigar estes problemas, recomenda-se as seguintes práticas:
- Envolvente só: use uma máquina virtual ou um computador secundário sem dados sensíveis críticos.
- Contas dedicadas: evite conectar suas contas principais; crie credenciais específicas para o agente.
- Entrada restrito: certifique-se de que a interface web do OpenClaw não esteja atingível via internet ensejo.
Formato do envolvente no Windows
O método mais seguro para a instalação utiliza o Subsistema Windows para Linux (WSL). Instalações diretas via PowerShell podem apresentar instabilidade.
1. Instalação do WSL
Caso ainda não possua o recurso ativo, abra o PowerShell porquê gestor e execute:
wsl --installPosteriormente a epílogo, reinicie o sistema se solicitado e verifique a instalação com o comando `wsl –version`. Para acessar o envolvente Linux, digite `wsl` no terminal.

2. Instalando o OpenClaw
Dentro do terminal WSL, inicie o script de instalação automática:
curl -fsSL | bashDurante o processo, siga as etapas de forma:
- Selecione Sim para os avisos de segurança.
- Escolha a opção Início Rápido (Quick Start).
- Na seleção de provedor de protótipo, opte por Ignorar por enquanto, pois a forma será feita para realização sítio.
- Em “Habilidades” (Skills) e instalação do Homebrew, selecione Não para agilizar o processo inicial.
- Anote o URL e o token de entrada exibidos no final do terminal; eles são necessários para acessar o quadro de controle.

Realização de LLMs Locais
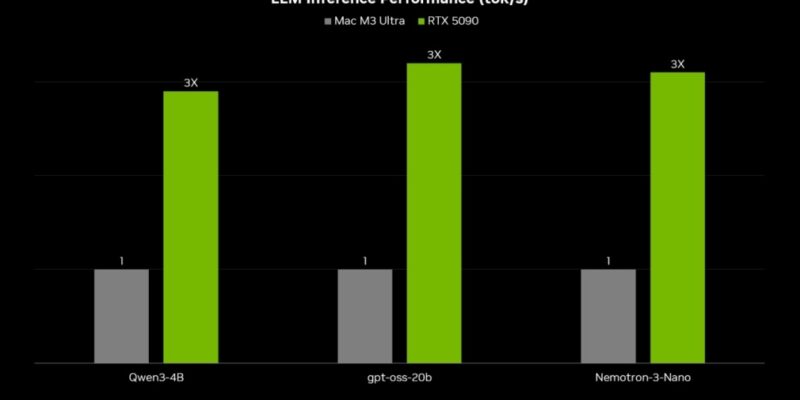
Para processar as informações sem internet, é preciso configurar um backend de IA. O desempenho dependerá da quantidade de VRAM disponível na sua placa de vídeo.
Escolha do Backend
Existem duas opções principais recomendadas para usuários de hardware NVIDIA:
- LM Studio: recomendado para performance bruta, utilizando Llama.cpp.
- Ollama: focado em facilidade de implantação e ferramentas para desenvolvedores.
Para instalar, execute o comando correspondente ao backend escolhido no terminal WSL:
LM Studio: curl -fsSL | bash
Ollama: curl -fsSL | sh
Seleção de Modelos por VRAM
A escolha do protótipo deve respeitar a memória de vídeo para evitar travamentos. Sugestões baseadas na capacidade da GPU:
- 8GB a 12GB: qwen3-4B-Thinking-2507
- 16GB: gpt-oss-20b
- 24GB a 48GB: Nemotron-3-Nano-30B-A3B
Posteriormente subtrair o protótipo (ex: `ollama pull gpt-oss:20b`), é necessário editar o registro `openclaw.json` localizado na pasta `.openclaw` para indicar para o servidor sítio (localhost), conforme detalhado na documentação solene da instrumento.
Com o gateway configurado e o protótipo onusto, basta acessar o link do quadro salvo anteriormente. O processamento sítio entrega maior privacidade, mas exige monitoramento estável do consumo de recursos do sistema.
Nascente(s): NVIDIA
Leia também:
- Clusters massivos de IA forçam indústria chinesa a transmigrar rapidamente para liquid cooling
- Meta confirma uso de CPUs NVIDIA Grace e mira ganhos de até 2X em performance por watt
- Operário japonesa de vasos sanitários pode ser peça-chave na demanda por memórias para IA

Vai dar *****!
Estudo afirma que uso de Lucidez Sintético não reduz o trabalho, mas aumenta











Comments